

Appearance
Nahrávání vlastních souborů
V Codexisu lze vlastní soubory využít na dvou místech:
- pro právní analýzu dokumentu
- v chatu s jakýmkoliv asistentem, kde lze rozšířit kontext o obsah nahraného dokumentu
Pokud preferujete nahrání anonymizovaného dokumentu, doporučujeme využít bezpečnou anonymizaci pomocí např.: https://www.ilovepdf.com/
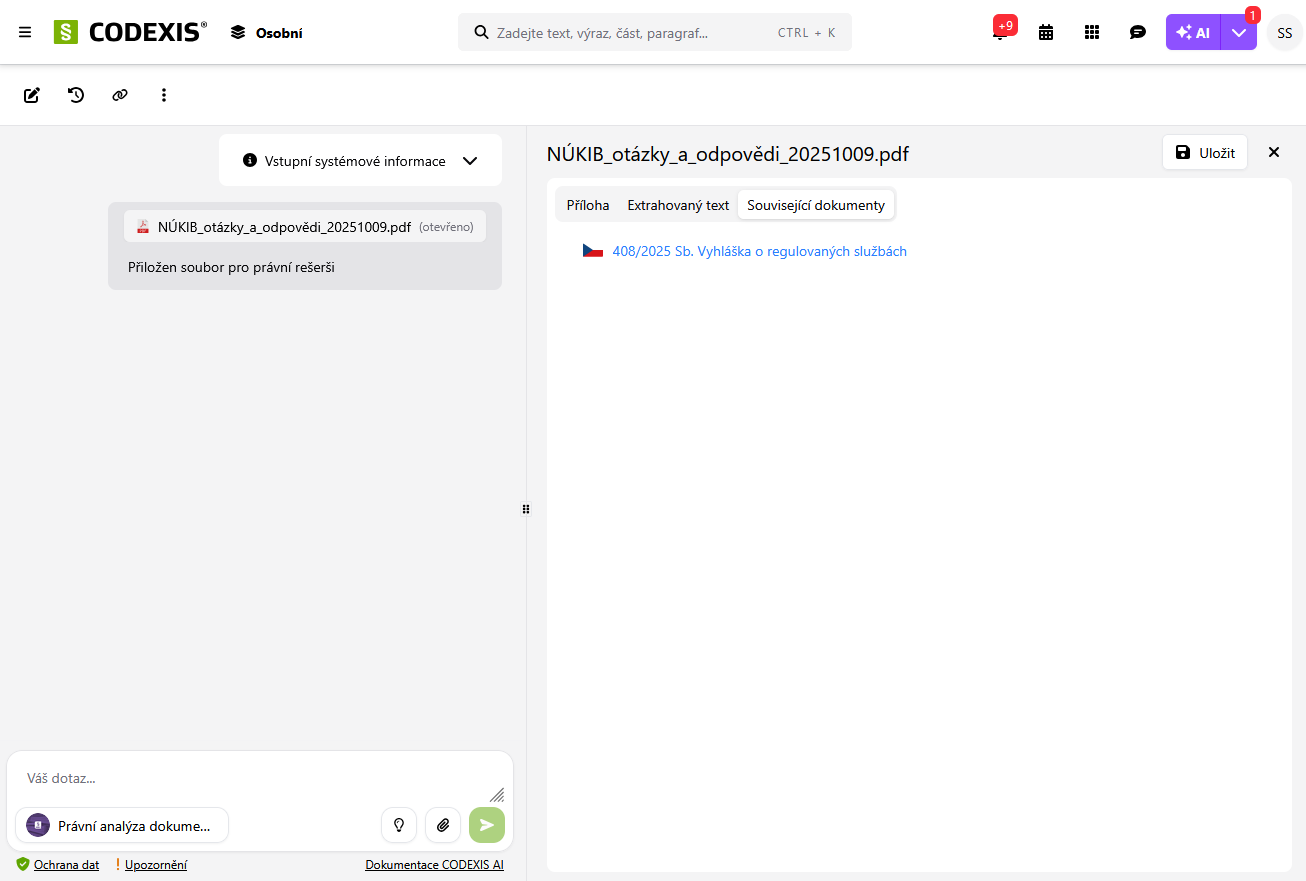
1. AI analýza vlastního souboru
AI analýza vlastního souboru v sobě kombinuje kontrolu aktuálnosti použitých právních předpisů a možnost analyzovat celý kontext souboru.
- analýzu spustíme z vyhledávacího řádku pomocí ikony upload souboru
- soubory lze nahrát z vlastního disku

V čem je tato funkce užitečná?
- po nahrání souboru proběhne kontrola použitých právních předpisů a jejich aktuálnosti
2. Rozšíření kontextu chatu vlastním dokumentem
Nahrání vlastního dokumentu přímo do chatu umožňuje rozšířit kontext existující konverzace. To znamená, že AI může přímo pracovat s obsahem vašeho souboru.
- dokument můžete přiložit k jakémukoliv chatu pomocí ikony přílohy (sponka)
- soubory lze nahrát z vlastního disku, nebo přímo z Mých témat
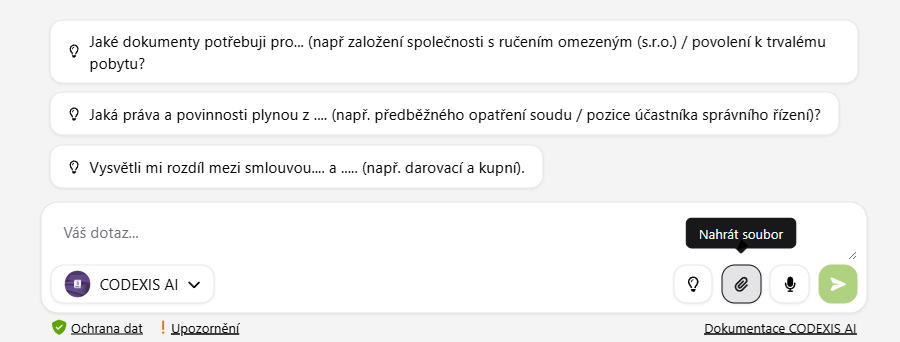
S nahranými soubory pak můžete například
- vygenerovat shrnutí obsahu pro rychlý přehled
- najít a zvýraznit klíčová ustanovení (např. výpovědní lhůty, sankce, rozhodčí doložky)
- najít potenciálně rizikové formulace (např. nevyvážené závazky)
- odhalit chybějící prvky běžné v daném typu smlouvy (např. GDPR doložka u pracovní smlouvy)
- nechat si dokument přeložit do jiného jazyka při zachování významu
- na základě analýzy navrhnout úpravy textu (např. doplnění ochranné doložky)
- vygenerovat alternativní znění sporných částí
- anebo jen rozšířit obsah stávajícího chatu
- apod.
Doporučení pro nahrávání souborů
- aby mohlo zpracování textu proběhnout rychle a přesně, nahrávejte menší a čitelné dokumenty
- ideálně do 200 stran
- doporučujeme Word (.docx) nebo PDF s textovou vrstvou
Proč ne více než 200 stran?
Velké soubory trvají déle a AI nemusí zvládnout zpracovat celý kontext najednou, což může ovlivnit přesnost výsledků.
Proč ne PDF bez textové vrstvy?
AI potřebuje textovou vrstvu, aby mohla dokument „číst“ a zpracovat obsah správně.
Pokud PDF obsahuje jen naskenovaný obrázek textu, systém provede OCR (optické rozpoznání textu).
Tento proces může trvat déle a kvalita výsledku odpovídá kvalitě skenu – rozmazané nebo pokřivené texty se rozpoznávají hůře.
Jak poznám, že PDF nemá textovou vrstvu?
Zkuste v souboru označit text myší. Pokud označení nejde a celé PDF se chová jako obrázek, jde o soubor bez textové vrstvy a bude nutný OCR převod.
Proč i PDF s textovou vrstvou může vracet špatné výsledky?
PDF může mít textovou vrstvu, ale obsahovat nesprávnou znakovou sadu nebo špatně zakódované znaky.
Při zpracování AI se takový dokument může jevit jako nečitelný. Problém lze ověřit vykopírováním textu do jednoduchého editoru (např. Notepad), kde se objeví otazníky nebo nesmyslné znaky.